בתור מראיין, אני הרבה פעמים שואל על איך HashMap עובד ב-Java. זה עוזר לי להעריך את ההבנה של המועמד במבני נתונים, ב-JVM internals ובגישה שלהם לפתרון בעיות. נתקלתי בהרבה מועמדים — ג’וניורים, מידים וסניורים — שלא הצליחו לענות על השאלה הזו נכון. אז החלטתי לשתף את התשובה עם כולם.
במאמר הזה אני אסביר את שאלת ה-HashMap צעד אחר צעד.
מה החוזה בין הפונקציות equals() ו-hashCode() ב-Java?

ב-Java, כל האובייקטים יורשים את הפונקציות equals() ו-hashCode() מקלאס Object. לפי הדוקומנטציה של equals(), יש צורך לעקוף גם את המתודה hashCode(). זה מבטיח שאובייקטים שווים יהיו בעלי hash codes שווים.
אם קוראים את הדוקומנטציה של equals(), אפשר להבחין בדברים הבאים:
Note that it is generally necessary to override the
hashCodemethod whenever this method is overridden, so as to maintain the general contract for thehashCodemethod, which states that equal objects must have equal hash codes.
אבל מה זה אומר?
זה אומר שאם יש לנו שני אובייקטים שנחשבים שווים, חייב להיות להם אותו hash code. אבל אם האובייקטים אינם שווים, אין ערובה שיהיו להם hash codes שונים.
מה המורכבות של שליפת אלמנט מ-HashMap?

שליפת אלמנט מ-HashMap היא בזמן קבוע של O(1).
קל! או שלא?
מה קורה אם hashCode() מוחזר לערך קבוע?
בואו נניח שכמפתח/ת, יצרתי את הקלאס הבא:
class MyClass {
@Override
public boolean equals(Object other) {
if (!(other instanceof MyClass)) return false;
return this == other;
}
@Override
public int hashCode() {
return 1;
}
}ועכשיו, בקוד שלי, אני יוצר מיליון אובייקטים ושומר אותם ב-HashMap:
Map<MyClass, Integer> map = new HashMap<>();
IntStream.range(0, 1_000_000)
.forEach(i -> map.put(new MyClass(), i));איך הפונקציה hashCode() החדשה תשפיע על הביצועים שלנו, אם בכלל?
כדי לענות על השאלה הזו, קודם צריך לצלול לתוך איך בדיוק HashMap עובד ב-Java.
כשמוסיפים אלמנט חדש ל-map שלנו, ה-hash code של המפתח מחושב קודם. לפי ערכו, נבחר bucket. ה-bucket הזה יכיל את הערך (במקרה הזה, האובייקט שלנו). במקרה של collision (2 אובייקטים או יותר עם אותו hash code), המפתח והערך נשמרים כזוג באמצעות מבנה נתונים כלשהו (למשל, linked list).
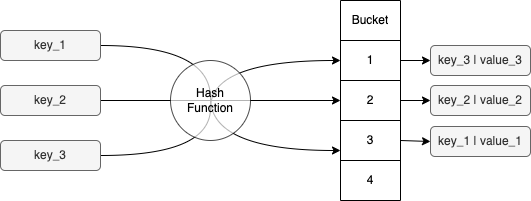
עכשיו בואו נניח שרוצים לקבל אלמנט מה-map. הפעולות הבאות יתרחשו:
ה-hash code של המפתח מחושב באמצעות הפונקציה
hashCode().ה-HashMap עובר על ה-linked list באמצעות הפונקציה
equals(). הוא יסיים כשימצא את הזוג הנכון של מפתחות וערכים.כשנמצא המפתח הנכון, הערך מוחזר, או null אם לא נמצא מפתח.
שימו לב שבדרך כלל ההנחה היא שפונקציית ה-hash מפוזרת באופן שווה. זה אומר שאנחנו מצפים למספר קטן מאוד של אלמנטים בכל bucket. לכן, החיפוש אחר המפתח הנכון יכול להיחשב כזמן קבוע.
אבל בדוגמה שלנו, כל המפתחות יהיו בעלי אותו hash code ולכן יגיעו לאותו bucket. לכן, קבלת ערך מה-map תצריך (במקרה הגרוע ביותר) סריקה של כל ה-linked list. זה ייקח זמן לינארי של O(n).
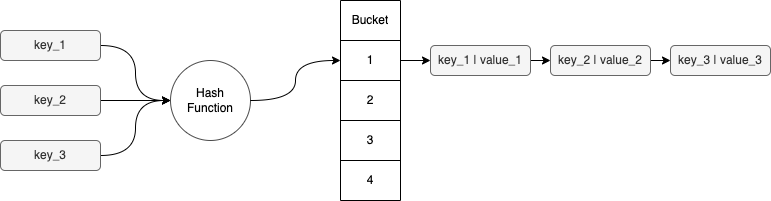
אפשר לשפר את זמן החיפוש?
הבעיה שלנו עכשיו היא שה-bucket משתמש ב-linked list — מבנה נתונים שאינו ממוין. מה אם היינו משתמשים במבנה נתונים שממוין מטבעו?
אפשר להחליף את מימוש ה-bucket בעץ בינארי מאוזן. על ידי כך, אנחנו יכולים להבטיח שכל אלמנט ב-bucket יכול להימצא עם מורכבות במקרה הגרוע של O(log(n)). זה הרבה יותר טוב ממה שהיה לנו קודם.
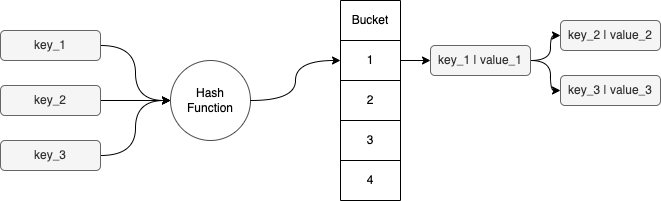
למעשה, מאז Java 8, המימוש הפנימי של HashMap השתנה בדיוק כך.
בונוס: מימוש HashSet באמצעות HashMap

בואו נתחיל עם השאלה — מה זה HashSet?
HashSet הוא set (אוסף לא מסודר של אלמנטים), שבו אותו hash code קיים רק פעם אחת.
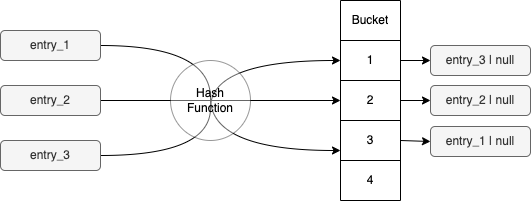
אפשר בקלות לממש HashSet באמצעות HashMap. נעשה זאת על ידי שימוש בערך שלנו ב-set כמפתח ל-map ו-null כערך. למעשה, זה בדיוק המימוש שבחרה Java.
סיכום
כפי שניתן לראות, השאלה מכסה תחומים רבים:
הבנה כללית של מבני נתונים
הבנה של Java internals
בדיקה איך המועמד/ת חושב/ת במקרה שלא זוכרים את ה-internals של Java (ברור שאף אחד לא מצפה לתשובת Wikipedia לשאלה הזו)
בנוסף, אפשר להרחיב את השאלה לנושאים נוספים כמו concurrency (למשל, איך מממשים distributed HashMap?).
משאבים
למידע נוסף, ראו את המשאבים הבאים: